posted 05-18-2008 08:47 PM

Here is a theoretical discussion of the problems of the MGQT, or more properly, the GQT and the family of MGQTs. The Federal Psychophysiological Detection of Deception Examiner's Handbook of 10/2006 uses the more general term Comparison Test Formats (CTF). Historically, it seems that Reid and Backster developed two distinct but largely similar versions of the comparison question technique, based the interpretation of differential reactivity and differences in the saliency of relevant and comparison questions, while recording physiological information about respiration, cardiovascular activity, and electrodermal activity.
Reid evolved his technique rather directly from the RI technique, by replacing the Irrelevant (neutral) Questions) at positions 6 and 10 with a Comparison Question. Ansley (1998) described some of the evolution from the Reid technique to the Army Zone, including the use of Backster type exclusive comparison questions, and numerical scoring.
Backster seems to have developed the Zone Comparison Technique (ZCT or Zone) from his evaluation of the theoretical problems surrounding polygraph testing, including the need for comparison questions, the desire to understand the distinctness or separation between the comparison and relevant questions, the possibility of outside influence and other factors.
Other variants of the MGQT have emerged, including the highly psychologized Marcy Technique, the Air Force MGQT. A previous edition of the AAPP polygraph examiner handbook included descriptions of the Navy MGQT and Secret Service MGQT, the latter of which seems now to be regarded a form of Air Force MGQT.
Both Reid and Backster have indoctrinated and imprinted generations of polygraph professionals, some of whom may be very competent, and some of whom have attempted to create and validate their own parochial versions, or schools of thought, around these basic methods.
The synchronicity of the evolution of new techniques is not unique. In the field of statistics, we saw the emergence of identical nonparametric methods known as the Mann-Whitney U test, and the Wilcoxon Rank-Sum test. These seem to have been published in different scientific journals within a short time of each other, and the historical consensus is that there was most likely no communication or plagiarism that occurred. It is simply a matter of timing, and the momentum of interest in non-parametric alternatives to the parametric two-sample t-test. These days, the technique is sometimes called the MWW U test or the Mann-Whitney-Wilcoxon rank sum test, in reference to all the people to did work on its development.
At their core, there are few differences between the types of test questions, physiological data, and basic scoring principles. Even the distinction between exclusive and non-exclusive CQs is now viewed as silly by people who have studied the data pertaining to these questions. Primary differences exist in target selection and question formulation and decision policies.
It is interesting to note that the trend of evolution from research and the study of data has tended to simplify our use and understanding of these polygraph techniques, while the improvements from trainers in field settings have involved more theoretical or psychologized solutions to potential problems. The intended function of symptomatics have generally not withstood the challenges of inquiry (Honts, Amato, & Gordon, 2000; Krapohl & Ryan 2001), nor has the overal truth question (Hiliard, 1979). Inside track questions have not been subject to any realistic investigation of the null-hypothesis.
I'll have to check, when I get home, but I believe Honts and Raskin (2002) describe the primary differences in Zone and MGQT techniques in terms of target selection and question formulation, in which the Zone approach has been to select the most intense behavioral issue or allegation and construct several semantically identical, though linguistically distinct, questions about that concern, and then interpret the test as a single issue. The MGQT approach is to construct several distinct investigation targets regarding distinct behavioral aspects of a single event or allegation, and interpret the questions with the hope that they will inform the investigator about the nature, role, or degree of involvement in the event or allegation. MGQT exams are, therefore, multi-facet examinations when used in the context of a known events or allegation. Backster calls the Zone an “exploratory” test when it involves multiple facets of a known incident. Under these circumstances the test is essentially an MGQT, and it causes misunderstanding and unnecessary division to insist on idiosyncratic language. It also degrades the primary value of any technique to deviate from an emphasis on its strengths in the false hope that a a single technique can become a panacea for all polygraph complications.
Differences in decision policies, for Zone and MGQT exams exist primarily in the emphasis in interpretation of the total score or test as a whole, compared with attempts to achieve an overall test result through the interpretation of results to individual test questions.
While most polygraph test developers seem to have been unfamiliar to commonly understood statistical complications inherent to the completion of multiple simultaneous significance tests, these differences can be observed in the common trends related to the outcomes of Zone and MGQT exams.
The results of single-issue Zone exams are easy to understand, because, by definition, it is inconceivable that an examinee could lie to one relevant question while being truthful to others. The results of multi-facet examinations becomes semantically and mathematically more complex, because these construction of these exams appears to be intended to improve the specificity of the test to the examinee's role of involvement in the known issue. Semantically, the axiom “DI to one means DI to all” is not so easily endorsed. This becomes even more evident when the MGQT format is adapted for use in mixed-issue screening examinations which commonly investigate several distinct behavioral concerns in the absence of any known allegations. In mixed issues exams it is conceivable that a person could lie regarding involvement in one behavior while being truthful regarding involvement in other behaviors.
The testing advantage of the mixed issue screening exam is intended to be increases sensitivity, to a broader range of behavioral issues. However, Barland, Honts, & Barger (1989) showed that mixed issues examination may not in fact provide the high level of sensitivity hoped for. There are understandable reasons for this phenomena.
Consider that all measurements are in fact estimates, and contain information from several dimensions, including the actual value of the phenomena we seek to measure, along with random measurement error resulting from psychological variability, physiological variability, and component sensor imperfections. For this reason, it is well understood in social and medical sciences that more stable estimates can be achieved by taking several measurements, and then aggregating the measurements together through either addition, averaging, standardization or other transformation. It is for this reason that proper scientific testing involves taking those several measurements in the same manner. For example: if I measure my son's linear height, it would contribute to a more stable measurement if a Measure his height two or three times, perhaps at the beginning and ending of a single day. It would not not, however, contribute to a more stable measurement if I had him stand on his toes for one of those measurements, simply because I want to maximize the linear distance from the floor. The point isn't to seek the maximum distance, but a stable estimate of the true distance. To use a metaphor (simile actually): if we wanted to sight in a hunting rifle we might put three rounds onto a single target, and then make some careful judgment about any necessary adjustment, based on the pattern on the target. That pattern is intended to be a representation of the variance of the weapon. It would make no sense to place the first round on the target from a prone position, the second while seated, and the third standing or kneeling. Doing so introduces an added dimension of variability to the data. Proper sighting is achieved by placing all rounds on the target using the same position/stance, grip, sight-picture, and trigger control.
If we imagine the single issue Zone exam as an attempt to shake apples from a tree (assuming there may be apples in the tree), we then get to stimulate or shake a single tree three different ways, and we get to complete the tree-shaking/stimulation experiment three or more times, for a total experiment involving nine different opportunities to shake apples from one tree. If we shake the tree vigorously enough, we are assured apples will fall if they are present. Having shaken the tree vigorously and to our satisfaction nine total times, we feel reasonably assured that no apples must be present if nothing has fallen.
In contrast, multi-facet examinations represent an experiment in which we have up to four different trees to shake, when evaluating for the presence or absence of apples. One major difference that is readily understood is that we will not be shaking a single tree nine times. Instead, we can now shake each tree only three to five times. The total volume of stimulation applied to each tree is therefore reduced, and this may be the condition underlying the results observed by Barland, Honts & Barland (1989).
So far, I have attempted to illustrate the sensitivity limitations. There are also specificity limitations with the technique. As you know, specificity, in polygraph, is the ability to correctly classify truthful cases. Deficits in specificity are related to both inconclusive results and false-positive errors.
Test accuracy, mathematically speaking, is really about variance. Accuracy of multi-facet and mixed issue examinations is about the variance of the individual spots. Attempts to define spot scores in terms of linear portions of total scores are mathematically negligent. Hint: its all about variance.
The challenges of the MGQT format also involve how we go about interpreting the collection of the several spot results. MGQT scoring rules provide a straightforward method. Fail any question and fail the test. Pass every question to pass the test; which also means that any inconclusive question will produce an inconclusive test result, unless one or more of the questions produces a deceptive score. Nevermind that most, if not all, of the research on MGQT decision cutscores is empirical only, with no real attempt to evaluate the variance of spot scores. Its still about variance, and the statistical rules that drive test results still drive the results of MGQT exam.
Now consider a base-rate problem. For this example, consider the MGQT format used in a LE screening exam. MGQTs make good LEPET and PCSOT formats, because the spot-scoring rules easily adapt to mixed issues situations. I know, someone will say a LEPET is not an MGQT; just think about it. So, pick three or four high-base rate behaviors. For “high,” lets say that >25% of persons are involved in the behavior or attempt to engage in deception regarding the behavior at their polygraph exams. I don't have any exact numbers, but lets imagine that 25% of applicants may under-report their use or recency of involvement in each of: 1) illegal drug use, 2) criminal activities, 3) violence, and 4) lying in their application/disclosure materials. Personally, I feel the last issue (lying to the booklet) is a terrible question, but I understand some agencies' desire to consider it a relevant investigation target. Is it reasonable to imagine that perhaps 25% of all applicants may be involved in each of those activities? If so, then the corollary means that 75% of all applicants are not involved in each. Combining them means that .75 * .75 * .75 * .75 = .32. Or, only 32% of your applicants are not involved in any of those activities. In a perfect setting, this means that 68% of LE applicants should fail their polygraphs. If we are seeing something different, it is a result of differing base rates, or adjustments to decision thresholds.
Now, factor in some imperfections. If we estimate a 5 to 10 % error rate, we have to add that estimation for each distinct relevant target (not the case with a single issue Zone). So, .5 + .5 + .5 + .5 = .20, or .1 + .1 + .1 + .1 = .40. So, our estimated FP error rate climbs quickly to 20 to 40 percent.
Then, look at the mathematical estimations for inconclusive results, which are estimated as:
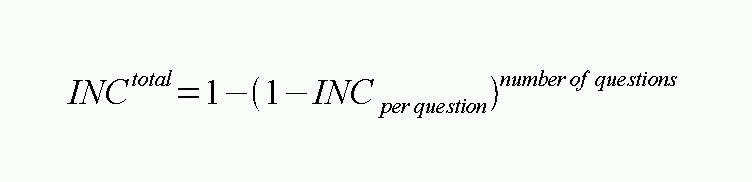
So, if we estimate a 5 to 10% inconclusive rate, then we can anticipate an inconclusive rate somewhere between 19 and 35% for four questions.
So, we have a test which may not be as sensitive as we hope, and which has some capacity for returning false-positive results, and a bunch of INCs.
There are more effective ways of aggregating the results of multi-facet and mixed issues exams, but that involves math that would put many field examiners to sleep. Procedural can be developed to approximate those mathematical solution in a more expedient manner, and that is what Senter (2003) and I think Senter & Dollins (2003) provide when they suggest that 2-stage rules may be more effective for MGQT exams than traditional MGQT decision policies.
Doubt this yet? Just ask an experienced examiner, who is not trying to BS you with some shell-game confidence-job. In reality, experienced examiners may learn techniques to mitigate or minimize these problems, but professional expertise of that type is largely informal and difficult to quantify.
So, lets look at the results of some studies:
Blackwell (1999) used confirmed ZCT (single issue) examinations to compare experienced federal examiners to the Polyscore 3.3 algorithm, and reported the experienced examiners showed a sensitivity level of .908. Sensitivity to deception is the proportion of deceptive case scored correctly, with inconclusives (7.7%) . Specificity to truthfulness was reported as .543. Specificity is the same as correctly classified confirmed truthful cases, with inconclusives (20.0%). Polygraph examiners often prefer to see results with inconclusives removed, because the results are more flattering. However, sensitivity and specificity with inconclusives provides a clearer representation of the effectiveness of a test. This does NOT mean that INCs are errors; they are simply a fact of life.
Blackwell (1999) also evaluated the results of experienced federal examiners with confirmed MGQT cases, and reported sensitivity = .975, with INC = .025, and specificity = .30, along with FPs = .45 and INCs = .25. If you haven't noticed, those numbers look at lot like the math I showed a few paragraphs back. Krapohl (2006) cited other studies (Krapohl & Norris, 2000; Podlesney & Truslow, 1993) with similar numbers.
The thing to keep in mind is that the 1999 study was completed with traditional ZCT scoring rules, including the spot scoring rule. Senter (2001; 2003), showed that the spot scoring rules improve sensitivity to deception, though at a cost of increased FP errors, and suggested a procedural solution to mitigate those errors. Krapohl (2005) provided additional evidence of the 2-stage solution to gaining the benefits of the SSR increase in sensitivity while reducing INC and FPs. In a statistical model, we would use some fancy math to achieve the same objective, and that is what OSS-3 does. 2-stage rules are a really good example of a simple procedural solution to approximate the mathematical principle. There may be other unexplored opportunities to improve the MGQT and other techniques through procedural or decision policy adjustments. Exploiting those opportunities and optimizing our methods will require that we be willing to tolerate scrutiny around identifiable deficits , and disengage from any pretense that any of our present techniques present a panacea or optimal alternative for all situations.
I'm not sure Eric's statements are about the AFMGQT, but may be about the MGQT in general. Perhaps Eric can clarify this.
There is still a lot for us all to learn.
.02
r

------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)


 Polygraph Place Bulletin Board
Polygraph Place Bulletin Board